Approssimazione con percettroni multistrato altamente configurabili
L'approssimazione di funzioni a una o più variabili, di curve e di superfici con una rete neurale
è un problema classico di machine learning e non richiede reti neurali con architetture sofisticate per ottenere risultati con accuratezza prossima al 100%:
è sufficiente un MLP (un percettrone multistrato, dall'inglese Multi-Layer Perceptron) ove il layer di input contiene tanti neuroni quanto è la dimensione del dominio
e il layer di output contiene tanti neuroni quanto è la dimensione del codominio mentre vi è una certa libertà di opzioni nello scegliere l'architettura degli strati nascosti,
le funzioni di attivazione, le funzioni di loss, l'ottimizzatore e i vari parametri di addestramento.
Su Internet si trovano numerosi esempi di MLP che approssimano questo tipo di oggetti matematici; tuttavia spesso tali esempi combinano in un unico script Python la generazione dei dataset
(con la funzione da approssimare hardcoded), il training del MLP, la predizione e la visualizzazione dei risultati; inoltre l'architettura della rete neurale è hardcoded
o poco parametrizzabile da linea di comando e infine le funzioni di attivazione, l'algoritmo di ottimizzazione usato e la funzione di loss sono molto spesso decisi dall'autore
senza una spiegazione che descriva le motivazioni della loro scelta.
La scarsa parametrizzazione, il ricorso a scelte implementate hardcoded e l'unificazione di varie funzionalità in un unico script rendono poco agevole la sperimentazione
e costringono lo sperimentatore a procedere per modifiche di codice al fine di realizzare e testare personalizzazioni del MLP e/o della procedura di addestramento.
Scopo di questa serie di post sull'approssimazione di funzioni, curve e superfici è di consentire all'utilizzatore di sperimentare diverse combinazioni di architettura MLP, funzioni di attivazione, algoritmo di addestramento e funzione di loss senza scrivere codice ma agendo solamente sulla linea di comando di quattro script Python che implementano separatamente le seguenti funzionalità:
- Creazione dei dataset: generazione di un file csv a partire da un oggetto matematico passato come argomento (quindi non hardcoded). Questa fase è opzionale in quanto i dataset potrebbero pre-esistere (come avviene nel mondo reale ad esempio estraendo curve da dati presenti su database o file Excel, dall'output di strumenti di misura, dai data-logger collegati a sensori elettronici, ecc) e quindi non necessariamente essere generati in modo sintetico.
- Definizione dell'architettura del MLP + Addestramento: configurazione dell'architettura degli strati nascosti del MLP con le relative funzioni di attivazione in uscita ed esecuzione della procedura di addestramento sul dataset di training consentendo di specificare la scelta dell'algoritmo di ottimizzazione, della funzione di loss e di altri parametri di addestramento.
- Predizione: applicazione del modello precedentemente addestrato a un dataset di input (che dovrebbe contenere dati mai visti dal modello in fase di addestramento) e generazione di un file csv di uscita con la predizione.
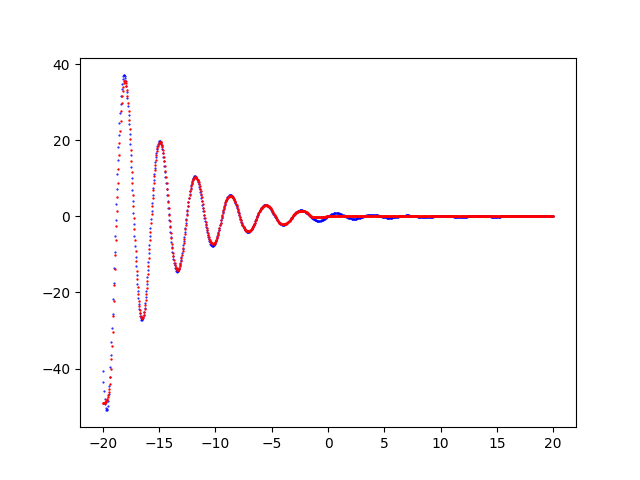
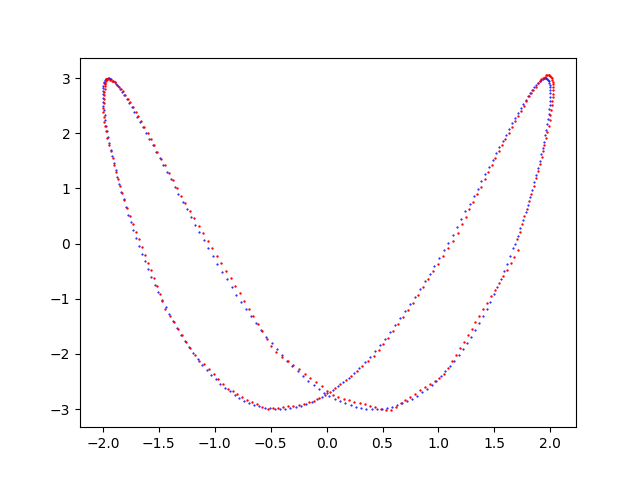
- Visualizzazione del risultato: generazione di un grafico che mostra la curva di un dataset di input e quella della predizione e consente la comparazione visuale. Questa fase è opzionale in quanto la predizione è salvata al passo precedente in un file csv ed è quindi già utilizzabile come tale.
Link ai post e al codice
La seguente tabella consente di accedere agli specifici post e al relativo codice delle varie tipologie di approssimatori: clickare sull'icona per visualizzare il post corrispondente e sull'icona per scaricare il codice disponibile su GitHub.