Forecast di una serie temporale univariata ed equispaziata con TensorFlow
Questo post tratta del forecast di una serie temporale univariata ed equispaziata tramite varie tassonomie di reti neurali implementate con TensorFlow. Il codice illustrato qui consente all'utilizzatore di poter testare diverse combinazioni di tipologie di rete (LSTM, LSTM Bidirezionali, Convoluzionali, ConvLSTM, Dense e alcune loro combinazioni in cascata) operando esclusivamente sulla linea di comando di una suite di programmi Python che implementano le seguenti funzionalità:
- Creazione dei dataset
- Definizione della tassonomia della rete + configurazione degli iperparametri
- Predizione (Forecast)
- Generazione del grafico dei risultati
- Generazione di un video sul processo di learning della rete
- Diagnostica
Per ottenere il codice si veda il paragrafo Download del codice completo in fondo a questo post.
Creazione dei dataset
Scopo del programma Python uvests_gen.py
è di generare i dataset (di training e/o di test) da utilizzare nelle fasi successive;
il programma prende in linea di comando la funzione generatrice della serie temporale in sintassi lambda body sulla variabile indipendente $t$, l'intervallo della variabile indipendente (inizio, fine e passo di discretizzazione)
e genera il dataset in un file nel formato csv applicando la funzione all'intervallo passato.
Il file csv in uscita ha una sola colonna (con header) che contiene i valori della variabile dipendente $y=f(t)$, ovverosia i valori della funzione $f(t)$ corrispondenti al valore di $t$ nell'intervallo specificato;
la variabile indipendente $t$ (il tempo) non è esplicitamente presente sul file in quanto il tempo nelle serie temporali equispaziate è implicito.
Per ottenere l'usage del programma è sufficiente eseguire il seguente comando:
$ python uvests_gen.py --helpuusage: uvests_gen.py [-h] [--version] --tsout TS_OUTPUT_FILENAME --funct
FUNC_T_BODY [--tbegin TIME_BEGIN] [--tend TIME_END]
[--tstep TIME_STEP] [--noise NOISE_BODY]
uvests_gen.py generates an univariate equally spaced time series
optional arguments:
-h, --help show this help message and exit
--version show program's version number and exit
--tsout TS_OUTPUT_FILENAME
univariate equally spaced time series output file (in
csv format)
--funct FUNC_T_BODY func(t) body (lamba format)
--tbegin TIME_BEGIN time begin (default:0)
--tend TIME_END time end (default:100)
--tstep TIME_STEP time step (default: 1.0)
--noise NOISE_BODY noise(sz) body (lamba format)-
-h, --help: mostra l'usage del programma e termina l'esecuzione.
-
--version: mostra la versione del programma e termina l'esecuzione.
-
--tsout: percorso (relativo o assoluto) del file csv da generare, che conterrà la serie temporale univariata ed equispaziata.
-
--funct: la funzione generatrice $y=f(t)$ della serie temporale in formato lamba body ove $t$ è la variabile indipendente.
-
--tbegin e --tend: intervallo della variabile $t$ tra
--tbegin(incluso) e--tend(escluso).
-
--tstep: passo di discretizzazione della variable indipendente $t$; il valore di default è 1.0.
-
--noise: la funzione generatrice di rumore in formato lamba body, ove $sz$ è il numero di elementi della serie.
Un esempio di uso del programma uvests_gen.py
Si supponga di voler generare una serie temporale per il training nell'intervallo $t \in [0,200)$ generata dalla seguente funzione $$f(t)=2 \sin \frac{t}{10}$$ con un passo di discretizzazione sulla variabile $t$ di $0.5$ e con un rumore bianco di ampiezza $0.02$ con una distribuzione normale di media $0$ e deviazione standard $1$. Tenendo presente che np è l'alias della libreria NumPy, la funzione generatrice si traduce in sintassi lambda body Python così:
2.0 * np.sin(t/10.0)0.02 * np.random.normal(0, 1, sz)$ python uvests_gen.py \
--tsout mytrain.csv \
--funct "2.0 * np.sin(t/10.0)" \
--tbegin 0 \
--tend 200 \
--tstep 0.5 \
--noise "0.02 * np.random.normal(0, 1, sz)"$ python uvests_gen.py \
--tsout myactual.csv \
--funct "2.0 * np.sin(t/10.0)" \
--tbegin 200.0 \
--tend 400.0 \
--tstep 0.5Definizione della tassonomia della rete + configurazione degli iperparametri
Scopo del programma Python fc_uvests_fit.py
è, in accordo con i parametri passati in linea di comando, creare dinamicamente una rete neurale ed effettuare il suo addestramento.
Per ottenere l'usage del programma è sufficiente eseguire il seguente comando:
$ python fc_uvests_fit.py --helpusage: fc_uvests_fit.py [-h] [--version] --tstrain TRAIN_TIMESERIES_FILENAME
--modelout MODEL_PATH [--samplelength SAMPLE_LENGTH]
[--subsamplelength SUB_SAMPLE_LENGTH]
[--bestmodelmonitor BEST_MODEL_MONITOR]
[--epochs EPOCHS] [--batchsize BATCH_SIZE]
[--convlstmlayers CONVLSTM_LAYERS_LAYOUT [CONVLSTM_LAYERS_LAYOUT ...]]
[--cnnlayers CNN_LAYERS_LAYOUT [CNN_LAYERS_LAYOUT ...]]
[--lstmlayers LSTM_LAYERS_LAYOUT [LSTM_LAYERS_LAYOUT ...]]
[--denselayers DENSE_LAYERS_LAYOUT [DENSE_LAYERS_LAYOUT ...]]
[--optimizer OPTIMIZER] [--loss LOSS]
[--metrics METRICS [METRICS ...]]
[--dumpout DUMPOUT_PATH] [--logsout LOGSOUT_PATH]
[--modelsnapout MODEL_SNAPSHOTS_PATH]
[--modelsnapfreq MODEL_SNAPSHOTS_FREQ]
fc_uvests_fit.py builds a model to fit an univariate equally spaced time
series using a configurable neural network
optional arguments:
-h, --help show this help message and exit
--version show program's version number and exit
--tstrain TRAIN_TIMESERIES_FILENAME
univariate equally spaced time series file (in csv
format) for training
--modelout MODEL_PATH
output model directory
--samplelength SAMPLE_LENGTH
length of the sample in terms of number of time steps
--subsamplelength SUB_SAMPLE_LENGTH
length of the sub sample in terms of number of time
steps (it must be a divisor of samplelength; used when
a ConvLSTM layer is present or when both Cnn and LSTM
layers are present, otherwise ignored)
--bestmodelmonitor BEST_MODEL_MONITOR
quantity name to monitor in order to save the best
model
--epochs EPOCHS number of epochs
--batchsize BATCH_SIZE
batch size
--convlstmlayers CONVLSTM_LAYERS_LAYOUT [CONVLSTM_LAYERS_LAYOUT ...]
ConvLSTM layer layout
--cnnlayers CNN_LAYERS_LAYOUT [CNN_LAYERS_LAYOUT ...]
CNN layer layout
--lstmlayers LSTM_LAYERS_LAYOUT [LSTM_LAYERS_LAYOUT ...]
LSTM layer layout
--denselayers DENSE_LAYERS_LAYOUT [DENSE_LAYERS_LAYOUT ...]
Dense layer layout
--optimizer OPTIMIZER
optimizer algorithm
--loss LOSS loss function name
--metrics METRICS [METRICS ...]
list of metrics to compute
--dumpout DUMPOUT_PATH
dump directory (directory to store loss and metric
values)
--logsout LOGSOUT_PATH
logs directory for TensorBoard
--modelsnapout MODEL_SNAPSHOTS_PATH
output model snapshots directory
--modelsnapfreq MODEL_SNAPSHOTS_FREQ
frequency in terms of epochs to make the snapshot of
model-
-h, --help: mostra l'usage del programma e termina l'esecuzione.
-
--version: mostra la versione del programma e termina l'esecuzione.
-
--tstrain: percorso (relativo o assoluto) del file csv (con header) che contiene la serie temporale da utilizzare per il training;
questo file può essere generato in modo sintetico dal precedente programma
uvests_gen.pyoppure essere una serie temporale non generata sinteticamente ma ottenuta realmente misurando a intervalli regolari di tempo un fenomeno.
-
--modelout: percorso (relativo o assoluto) della directory dove salvare il modello nel formato nativo di Keras per TensorFlow.
-
--samplelength: lunghezza dei campioni in termini di numero di passi di tempo.
-
--subsamplelength: lunghezza dei sottocampioni, sempre in termini di numero di passi di tempo. Questo parametro è obbligatorio se il primo layer nascosto della rete (quello dopo il layer di input) è di tipo ConvLSTM oppure CNN-LSTM,
altrimenti tale parametro è ignorato; quando è necessario deve essere un divisore di
--samplelength.
-
--bestmodelmonitor: il nome della metrica da utilizzare per salvare nella directory specificata da
--modeloutil modello con il miglior valore di questa metrica incontrato al trascorrere delle epoche; se non specificato verrà salvato il modello all'ultima epoca.
-
--epochs: numero di epoche del processo di training.
-
--batchsize: lunghezza dei batch usati nel processo di training.
-
--convlstmlayers: configurazione dei layer di tipo ConvLSTM; le tipologie supportate sono:
- convlstm(filters, kernel_size, activation, kinit, binit): aggiunge un layer ConvLSTM2D nel layout dei layer di tipo ConvLSTM con i parametri specificati (kinit e binit, che sono gli inizializzatori del kernel e del bias, sono opzionali).
- dropout(rate): aggiunge un layer Dropout nel layout dei layer di tipo ConvLSTM con il rate specificato.
-
--cnnlayers: configurazione dei layer di tipo CNN; le tipologie supportate sono:
- conv(filters, kernel_size, activation, kinit, binit): aggiunge un layer Conv1D nel layout dei layer di tipo CNN con i parametri specificati (kinit e binit, che sono gli inizializzatori del kernel e del bias, sono opzionali).
- maxpool(pool_size): aggiunge un layer MaxPooling1D nel layout dei layer di tipo CNN con la dimensione del pool specificata.
- dropout(rate): aggiunge un layer Dropout nel layout dei layer di tipo CNN con il rate specificato.
-
--lstmlayers: configurazione dei layer di tipo LSTM; le tipologie supportate sono:
- lstm(units, activation, kinit, binit): aggiunge un layer LSTM nel layout dei layer di tipo LSTM con i parametri specificati (kinit e binit, che sono gli inizializzatori del kernel e del bias, sono opzionali).
- lstmbi(units, activation, kinit, binit): aggiunge un layer Bidirectional LSTM nel layout dei layer di tipo LSTM on i parametri specificati (kinit e binit, che sono gli inizializzatori del kernel e del bias, sono opzionali).
- dropout(rate): aggiunge un layer Dropout nel layout dei layer di tipo LSTM con il rate specificato.
-
--denselayers: configurazione dei layer di tipo Dense; le tipologie supportate sono:
- dense(units, activation, kinit, binit): aggiunge un layer Dense nel layout dei layer di tipo Dense con i parametri specificati (kinit e binit, che sono gli inizializzatori del kernel e del bias, sono opzionali).
- dropout(rate): aggiunge un layer Dropout nel layout dei layer di tipo Dense con il rate specificato.
-
--optimizer: chiamata al costruttore dell'ottimizzatore usato dal processo di training; si veda il reference di TensorFlow 2.x Optimizators per dettagli
sui parametri supportati dai costruttori degli algoritmi. Il default è Adam(), gli algoritmi disponibili sono:
- Adadelta()
- Adagrad()
- Adam()
- Adamax()
- Ftrl()
- Nadam()
- RMSprop()
- SGD()
-
--loss: Chiamata al costruttore della funzione di loss (costo) usata dal processo di training; si veda il reference di TensorFlow 2.x Loss Functions per dettagli
sui parametri supportati dai costruttori delle funzioni di loss. Il default è MeanSquaredError(), le funzioni di loss disponibili sono:
- BinaryCrossentropy()
- CategoricalCrossentropy()
- CategoricalHinge()
- CosineSimilarity()
- Hinge()
- Huber()
- KLDivergence()
- LogCosh()
- MeanAbsoluteError()
- MeanAbsolutePercentageError()
- MeanSquaredError()
- MeanSquaredLogarithmicError()
- Poisson()
- Reduction()
- SparseCategoricalCrossentropy()
- SquaredHinge()
-
--metrics: sequenza di nomi di metriche; si veda la documentazione di TensorFlow 2.x Metrics; comunque le metriche che hanno senso in questo constesto sono:
- mean_squared_error
- mean_squared_logarithmic_error
- mean_absolute_error
- mean_absolute_percentage_error
-
--dumpout: percorso (relativo o assoluto) della directory dove salvare i valori delle metriche e della funzione di loss allo scorrere delle epoche;
il programma
nn_dumps_scatter.pyutilizzerà il contenuto di questa directory per visualizzare i grafici delle metriche e della funzione di loss.
-
--logsout: percorso (relativo o assoluto) della directory dove salvare i log della fase di training
affinché li si possa analizzare tramite TensorBoard
-
--modelsnapout: percorso (relativo o assoluto) della directory dove salvare uno snapshot del modello coorrente alla i-esima epoca;
la frequenza con cui effettuare il salvataggio è specificata dal parametro
--modelsnapfreq. Il programmafc_uvests_video.py, utilizzando gli snapshot dei modelli salvati ogni--modelsnapfreqepoche, genera un video per mostrare come la rete impara al trascorrere delle epoche.
-
--modelsnapfreq: indica ogni quante epoche effettuare un salvataggio del modello della directory indicata da
--modelsnapout.
Un esempio di uso del programma fc_uvests_fit.py
Dopo aver generato tramite uvests_gen.py la serie di training, si intente adesso creare una rete neurale con un layer LSTM
seguto da due layer Dense ed effettuare un training con 100 epoche con batch size di 40 valori usando l'ottimizzatore Adam e MeanSquaredError quale funzione di loss.
Si esegua quindi il seguente comando:
$ python fc_uvests_fit.py \
--tstrain mytrain.csv \
--samplelength 12 \
--modelout mymodel \
--lstmlayers "lstm(200, 'tanh')" \
--denselayers "dense(80, 'tanh')" "dense(80, 'tanh')" \
--epochs 100 \
--batchsize 40 \
--optimizer "Adam(learning_rate=1e-3, epsilon=1e-07)" \
--loss "MeanSquaredError()"mymodel conterrà il modello della rete con la tassonomia specificata e addestrata secondo gli iperparametri passati in linea di comando.
Predizione (Forecast)
Scopo del programma Python fc_uvests_predict.py
è di calcolare la predizione (il forecast) della serie temporale imparata nella fase di training.
Per ottenere l'usage del programma è sufficiente eseguire il seguente comando:
$ python fc_uvests_predict.py --helpusage: fc_uvests_predict.py [-h] [--version] --model MODEL_PATH --tstrain
TIMESERIES_FILENAME [--tsactual ACTUAL_FILENAME]
[--strategy recursive,walk_forward]
[--samplelength SAMPLE_LENGTH]
[--subsamplelength SUB_SAMPLE_LENGTH]
[--fclength FORECAST_LENGTH]
--tsforecastout FORECAST_DATA_FILENAME
[--error ERROR]
fc_uvests_predict.py compute forecasting of an univariate equally spaced time
series
optional arguments:
-h, --help show this help message and exit
--version show program's version number and exit
--model MODEL_PATH model directory path
--tstrain TIMESERIES_FILENAME
univariate equally spaced time series file (in csv
format) used for training
--tsactual ACTUAL_FILENAME
actual univariate equally spaced time series file (in
csv format)
--strategy recursive,walk_forward
recursive uses previous predictions as input for
future predictions, walk_forward uses actual as input
for future predictions (default: recursive)
--samplelength SAMPLE_LENGTH
length of the sample in terms of number of time steps
used for training
--subsamplelength SUB_SAMPLE_LENGTH
length of the sub sample in terms of number of time
steps used for training (it must be a divisor of
samplelength; used when a ConvLSTM layer is present or
when both CNN and LSTM layers are present, otherwise
ignored)
--fclength FORECAST_LENGTH
length of forecast (number of values to predict)
--tsforecastout FORECAST_DATA_FILENAME
output forecast data file (in csv format)
--error ERROR error function name
-
-h, --help: mostra l'usage del programma e termina l'esecuzione.
-
--version: mostra la versione del programma e termina l'esecuzione.
-
--model: percorso (relativo o assoluto) della directory del modello salvato da
fc_uvests_fit.pye specificato dall'argomento--modelout.
-
--tstrain: percorso (relativo o assoluto) del file csv (con header) che contiene la serie temporale utilizzata per il training,
ovverosia quella passata al precedente programma
fc_uvests_fit.py.
-
--tsactual: percorso (relativo o assoluto) del file csv (con header) che contiene la serie temporale di test;
è obbligatoria se
--strategyèwalk_forward; se presente tale serie viene considerata immediatamente seguente a quella di training.
-
--strategy: indica la strategia di predizione: i valori ammessi sono
recursiveewalk_forward.- recursive: i valori della predizione sono usati come input per calcolare i valori di forecast successivi.
-
walk_forward: i valori della serie specificata in
--tsactualsono usati come input per calcolare il forecast.
-
--samplelength: lunghezza dei campioni in termini di numero di passi di tempo.
Deve essere lo stesso identico valore passato a
fc_uvests_fit.pytramite l'argomento--samplelength.
-
--subsamplelength: lunghezza dei sottocampioni, sempre in termini di numero di passi di tempo. Questo parametro è obbligatorio se il primo layer nascosto della rete (quello dopo il layer di input) è di tipo ConvLSTM oppure CNN-LSTM,
altrimenti tale parametro è ignorato; quando obbligatorio deve essere lo stesso identico valore passato a
fc_uvests_fit.pytramite l'argomento--subsamplelength.
-
--fclength: indica il numero di predizioni da effettuare;
se
--strategyèwalk_forward, la lunghezza della serie specificata in--tsactualdeve contenere un numero di elementi maggiore o uguale al valore passato in--fclength
-
--tsforecastout: percorso (relativo o assoluto) del file csv da generare che conterrà la predizione, ovverosia la serie temporale di forecast (naturalmente univariata ed equispaziata allo stesso modo della serie temporale di training).
-
--error: il nome della funzione di errore da calcolare tra la serie temporale di forecast e la serie temporale di test.
Un esempio di uso del programma fc_uvests_predict.py
Dopo aver effettuato la creazione del modello tramite fc_uvests_fit.py si intente finalmente calcolare il forecast
e confrontare il forecast predetto con la serie temporale di test e quindi calcolare il valore dell'errore tra le due serie.
Si esegua quindi il seguente comando:
$ python fc_uvests_predict.py \
--tstrain mytrain.csv \
--tsactual myactual.csv \
--strategy recursive \
--samplelength 12 \
--fclength 400 \
--model mymodel \
--tsforecastout myforecast.csv \
--error "MeanSquaredError()"myforecast.csv conterrà la serie temporale di forecast.
Generazione del grafico dei risultati
Scopo del programma Python fc_uvests_scatter.py
è di visualizzare graficamente la serie di training (punti blu), la serie di forecast (punti rossi) e opzionalmente la serie temporale di test (punti verdi).
Per ottenere l'usage del programma è sufficiente eseguire il seguente comando:
$ python fc_uvests_scatter.py --helpusage: fc_uvests_scatter.py [-h] [--version] --tstrain TIMESERIES_FILENAME
--tsforecast FORECAST_FILENAME
[--tsactual ACTUAL_FILENAME]
[--title FIGURE_TITLE] [--tlabel T_AXIS_LABEL]
[--ylabel Y_AXIS_LABEL]
[--labelfontsize LABEL_FONT_SIZE] [--width WIDTH]
[--height HEIGHT] [--savefig SAVE_FIGURE_FILENAME]
fc_uvests_scatter.py shows two joined x/y scatter graphs:
the blue one is the univariate equally spaced time series
the red one is the forecast
the optional green one is the actual univariate equally spaced time series
optional arguments:
-h, --help show this help message and exit
--version show program's version number and exit
--tstrain TIMESERIES_FILENAME
univariate equally spaced time series file (in csv format) used for training
--tsforecast FORECAST_FILENAME
forecast file (in csv format)
--tsactual ACTUAL_FILENAME
univariate equally spaced actual file (in csv format)
--title FIGURE_TITLE if present, it set the title of chart
--tlabel T_AXIS_LABEL
label of t axis
--ylabel Y_AXIS_LABEL
label of y axis
--labelfontsize LABEL_FONT_SIZE
label font size
--width WIDTH width of animated git (in inch)
--height HEIGHT height of animated git (in inch)
--savefig SAVE_FIGURE_FILENAME
if present, the chart is saved on a file instead to be shown on screen-
-h, --help: mostra l'usage del programma e termina l'esecuzione.
-
--version: mostra la versione del programma e termina l'esecuzione.
-
--tstrain: percorso (relativo o assoluto) del file csv (con header) che contiene la serie temporale utilizzata per il training,
ovverosia quella passata al precedente programma
fc_uvests_fit.py.
-
--tsforecast: percorso (relativo o assoluto) del file csv (con header) che contiene la serie temporale di forecast;
questo file è generato dal precedente programma
fc_uvests_predict.pyed è il file specificato nell'argomento--tsforecastout.
-
--tsactual: percorso (relativo o assoluto) del file csv (con header) che contiene la serie temporale di test;
è obbligatoria se
--strategyèwalk_forwarde se presente tale serie viene considerata immediatamente seguente a quella di training.
-
--title: imposta il titolo del grafico.
-
--tlabel: imposta l'etichetta dell'asse $t$ del grafico (le ascisse).
-
--ylabel: imposta l'etichetta dell'asse $y$ del grafico (le ordinate).
-
--labelfontsize: imposta la grandezza del font dei testi presenti nell'immagine.
-
--width: imposta la larghezza dell'immagine generata, in inch
-
--height: imposta l'altezza dell'immagine generata, in inch
-
--savefig: percorso (relativo o assoluto) del file immagine (in formato png) da salvare;
se non presente il grafico è mostrato a video in una finestra.
Un esempio di uso del programma fc_uvests_scatter.py
Dopo aver effettuato la creazione del modello tramite fc_uvests_fit.py, si intente finalmente calcolare il forecast
e confrontare il forecast predetto con la serie temporale di test e quindi calcolare il valore di l'errore tra le due serie.
Si esegua quindi il seguente comando:
$ python fc_uvests_scatter.py \
--tstrain mytrain.csv \
--tsforecast myforecast.csv \
--tsactual myactual.csv \
--title "My example" \
--tlabel "t" \
--ylabel "y" \
--savefig myexample.pngmyexample.png conterrà il grafico delle tre serie temporali.
Nota: Data la natura stocastica della fase di addestramento, i singoli specifici risultati possono variare. Si consideri di eseguire la fase di addestramento più volte.
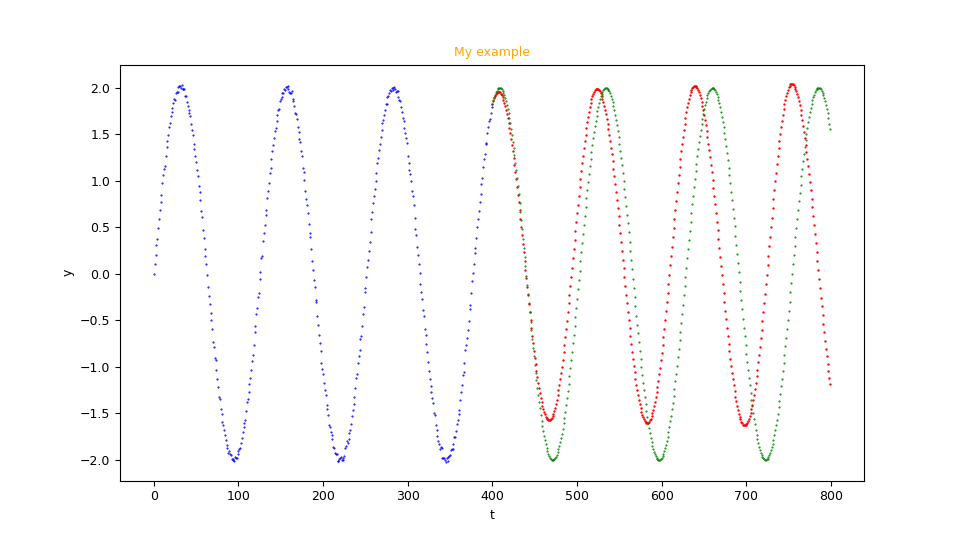
Esempio di immagine generata dal programma
fc_uvests_scatter.py.Generazione di un video sul processo di learning della rete
Scopo del programma Python fc_uvests_video.py
è di generare un video (precisamente una git animata) che mostri la predizione (il forecast) allo scorrere delle epoche durante la fase di training.
Per la generazione di tale video è necessario passare al comando fc_uvests_fit.py gli argomenti --modelsnapout e --modelsnapfreq.
Per ottenere l'usage del programma è sufficiente eseguire il seguente comando:
$ python fc_uvests_video.py --helpusage: fc_uvests_video.py [-h] [--version] --modelsnap MODEL_SNAPSHOTS_PATH
--tstrain TIMESERIES_FILENAME
[--tsactual ACTUAL_FILENAME]
[--strategy recursive,walk_forward]
[--samplelength SAMPLE_LENGTH]
[--subsamplelength SUB_SAMPLE_LENGTH]
[--fclength FORECAST_LENGTH] --savevideo
SAVE_GIF_VIDEO [--title FIGURE_TITLE_PREFIX]
[--tlabel T_AXIS_LABEL] [--ylabel Y_AXIS_LABEL]
[--labelfontsize LABEL_FONT_SIZE]
[--frameperseconds FRAME_PER_SECONDS]
[--width WIDTH] [--height HEIGHT]
fc_uvests_video.py generates an animated git that shows the forecast curve
computed on an input univariate equally spaced time series as the epochs
change.
optional arguments:
-h, --help show this help message and exit
--version show program's version number and exit
--modelsnap MODEL_SNAPSHOTS_PATH
model snapshots directory (generated by uts_fit.py
with option --modelsnapout)
--tstrain TIMESERIES_FILENAME
univariate equally spaced time series file (in csv
format) used for training
--tsactual ACTUAL_FILENAME
actual univariate equally spaced time series file (in
csv format)
--strategy recursive,walk_forward
recursive uses previous predictions as input for
future predictions, walk_forward uses actual as input
for future predictions (default: recursive)
--samplelength SAMPLE_LENGTH
length of the sample in terms of number of time steps
used for training
--subsamplelength SUB_SAMPLE_LENGTH
length of the sub sample in terms of number of time
steps used for training (it must be a divisor of
samplelength; used when a ConvLSTM layer is present or
when both CNN and LSTM layers are present, otherwise
ignored)
--fclength FORECAST_LENGTH
length of forecast (number of values to predict)
--savevideo SAVE_GIF_VIDEO
the animated .gif file name to generate
--title FIGURE_TITLE_PREFIX
if present, it set the prefix title of chart
--tlabel T_AXIS_LABEL
label of t axis
--ylabel Y_AXIS_LABEL
label of y axis
--labelfontsize LABEL_FONT_SIZE
label font size
--frameperseconds FRAME_PER_SECONDS
frame per seconds
--width WIDTH width of animated git (in inch)
--height HEIGHT height of animated git (in inch)-
-h, --help: mostra l'usage del programma e termina l'esecuzione.
-
--version: mostra la versione del programma e termina l'esecuzione.
-
--tstrain: si veda l'omonimo argomento di
fc_uvests_predict.py.
-
--tsactual: si veda l'omonimo argomento di
fc_uvests_predict.py.
-
--strategy: si veda l'omonimo argomento di
fc_uvests_predict.py.
-
--samplelength: si veda l'omonimo argomento di
fc_uvests_predict.py.
-
--subsamplelength: si veda l'omonimo argomento di
fc_uvests_predict.py.
-
--fclength: si veda l'omonimo argomento di
fc_uvests_predict.py.
-
--savevideo: percorso (relativo o assoluto) del file video (in formato git animata) da generare.
-
--title: imposta il titolo del video.
-
--tlabel: imposta l'etichetta dell'asse $t$ del grafico (le ascisse) contenuto nel video.
-
--ylabel: imposta l'etichetta dell'asse $y$ del grafico (le ordinate) contenuto nel video.
-
--labelfontsize: imposta la grandezza del font dei testi presenti nel video.
-
--frameperseconds: imposta il numero di frame per secondo del video.
-
--width: imposta la larghezza del video, in inch
-
--height: imposta l'altezza del video, in inch
Un esempio di uso del programma fc_uvests_video.py
Rieseguendo prima il programma fc_uvests_fit.py aggiungendo gli argomenti --modelsnapout e --modelsnapfreq,
passando ad esempio rispettivamente mysnaps e 5
e successivamente eseguire il seguente comando:
$ python fc_uvests_video.py \
--modelsnap mysnaps \
--tstrain mytrain.csv \
--tsactual myactual.csv \
--strategy recursive \
--samplelength 12 \
--fclength 400 \
--savevideo myvideo.gif \
--title "My example" \
--tlabel "t" \
--ylabel "y"myvideo.gif conterrà una gif animata che mostra una sequenza di frame
e ogni frame mostra il grafico del forecast calcolato con il modello disponibile alla i-esima epoca.
Diagnostica
La suite offre quattro tecniche per effettuare diagnostica; la prima è evidente e sono i messaggi utente scritti
sullo standard output e sullo standard error dei vari programmi; la seconda è la generazione del video descritta sopra,
in quanto quel video consente di osservare come la rete neurale stia imparando con il passare delle epoche.
La terza tecnica è di utilizzare TensorBoard: è necessario eseguire il programma fc_uvests_fit.py con l'argomento --logsout
in cui si specifica una directory ove il programma scriverà i log file che TensorBoard analizza sia durante che al termine della fase di training.
Si veda la pagina di TensorBoard per dettagli.
La quarta tecnica è quella di far calcolare delle metriche alil programma fc_uvests_fit.py specificando l'argomento --metrics;
il valore delle metriche calcolato ad ogni epoca è visualizzato sullo standard output, così come il valore della funzione di loss,
ma specificando un percorso di una directory nell'argomento --dumpout i valori della funzione di loss e delle metriche sono salvati
in file csv in tale directory; tali file sono poi visualizzabili graficamente utilizzando il programma nn_dumps_scatter.py.
Per ottenere l'usage del programma è sufficiente eseguire il seguente comando:
$ python nn_dumps_scatter.py --helpusage: nn_dumps_scatter.py [-h] [--version] --dump DUMP_PATH
[--savefigdir SAVE_FIGURE_DIRECTORY]
nn_dumps_scatter.py shows the loss and metric plots with data generated by
fc_uvests_fit.py with argument --dumpout
optional arguments:
-h, --help show this help message and exit
--version show program's version number and exit
--dump DUMP_PATH dump directory (generated by any fitting/training
programs of this suite that support --dumpout argument)
--savefigdir SAVE_FIGURE_DIRECTORY
if present, the charts are saved on files in
savefig_dir folder instead to be shown on screen-
-h, --help: mostra l'usage del programma e termina l'esecuzione.
-
--version: mostra la versione del programma e termina l'esecuzione.
-
--dump: percorso (relativo o assoluto) della directory dove
fc_uvests_fit.py(tramite l'argomento--dumpout) ha salvato i valori delle metriche e della funzione di loss allo scorrere delle epoche.
-
--savefig: percorso (relativo o assoluto) di una directory ove salvare le immagini dei grafici (in formato png);
se non presente i grafici sono mostrato a video in finestre.
Un esempio di uso del programma nn_dumps_scatter.py
Rieseguendo prima il programma fc_uvests_fit.py aggiungendo l'argomento --dumpout
passando ad esempio mydump e successivamente eseguire il seguente comando:
$ python nn_dumps_scatter.py \
--dump mydump
--savefigdir mydiagnostic
Esempi di uso in cascata dei programmi della suite
Nella cartella examples
ci sono alcuni programmi shell che mostrano l'uso dei programmi della suite in cascata in varie combinazioni
di iperparametri, dataset e forecast.
Nota: Data la natura stocastica di questi esempi (dovuta alla parte di training), i singoli specifici risultati possono variare. Si consideri di eseguire i singoli esempi più volte.
Download del codice completo
Il codice completo è disponibile su GitHub.
Questo materiale è distribuito su licenza MIT; sentiti libero di usare, condividere, "forkare" e adattare tale materiale come credi.
Sentiti anche libero di pubblicare pull-request e bug-report su questo repository di GitHub oppure di contattarmi sui miei canali social disponibili nell'angolo in alto a destra di questa pagina.