Strumenti generali per l'approssimazione di funzioni
Questo post descrive l'uso di un insieme di strumenti generali scritti in Python
per generare e visualizzare dataset sintetici ottenuti eseguendo funzioni generatrici sia scalari che vettoriali a una o più variabili
oppure dataset ottenuti approssimando tali funzioni tramite opportuni programmi descritti in altri post di questo sito web
che trattano l'approssimazione di oggetti matematici (funzioni, curve e superfici) sia con algoritmi di machine learning che con reti neurali.
Le aree interessate da questi strumenti sono:
- Creazione dei dataset sintetici
- Visualizzazione comparata dei dataset
- Diagnostica
Per ottenere il codice di ciascuno strumento si segua il link presente all'inizio di ogni paragrafo relativo allo strumento stesso; il paragrafo Download del codice completo contiene il link all'intero repository che tratta l'approssimazione delle funzioni matematiche con tecniche di machine e deep learning.
Creazione dei dataset sintetici
Questo capitolo illustra gli strumenti per la generazione dataset sintetici a partire da funzioni matematiche generatrici.
fx_gen.py
Scopo del programma Python fx_gen.py
è di generare un dataset sintetico in formato csv a partire da una funzione generatrice scalare reale di una variabile reale in un intervallo chiuso specificando il passo di discretizzazione.
Il file csv in uscita ha due colonne (con header): la prima colonna contiene i valori, ordinati in modo crescente, della variabile indipendente $x$ nell'intervallo desiderato con il passo di discretizzazione specificato;
la seconda colonna contiene i valori della variabile dipendente, ovverosia i valori della funzione $f(x)$ corrispondenti al valore di $x$ della prima colonna.
Per ottenere l'usage del programma è sufficiente eseguire il seguente comando:
$ python fx_gen.py --helpusage: fx_gen.py [-h] [--version] --dsout DS_OUTPUT_FILENAME --funcx
FUNC_X_BODY [--xbegin RANGE_BEGIN] [--xend RANGE_END]
[--xstep RANGE_STEP] [--noise NOISE_BODY]
fx_gen.py generates a synthetic dataset file calling a one-variable real
function in an interval
optional arguments:
-h, --help show this help message and exit
--version show program's version number and exit
--dsout DS_OUTPUT_FILENAME
dataset output file (csv format)
--funcx FUNC_X_BODY f(x) body (lamba format)
--xbegin RANGE_BEGIN begin range (default:-5.0)
--xend RANGE_END end range (default:+5.0)
--xstep RANGE_STEP step range (default: 0.01)
--noise NOISE_BODY noise(sz) body (lamba format)-
-h, --help: mostra l'usage del programma e termina l'esecuzione.
-
--version: mostra la versione del programma e termina l'esecuzione.
-
--dsout: percorso (relativo o assoluto) del file csv da generare ed è ottenuto eseguendo la funzione generatrice del dataset.
-
--funcx: la funzione generatrice $y=f(x)$ del dataset in formato lamba body ove $x$ è la variabile indipendente.
-
--xbegin e --xend: intervallo chiuso della variabile indipendente $x$ tra
--xbegine--xend.
-
--xstep: passo di discretizzazione della variable indipendente $x$.
-
--noise: la funzione generatrice di rumore in formato lamba body, ove $sz$ è
il numero di elementi dell'intervallo discretizzato tra
--xbegine--xend.
Un esempio di uso del programma fx_gen.py
Si supponga di voler approssimare nell'intervallo $[-6.0,6.0]$ la seguente funzione $$f(x)=\sqrt{|x|}$$ Tenendo presente che np è l'alias della libreria NumPy, questa si traduce in sintassi lambda body Python così:
np.sqrt(np.abs(x))$ python fx_gen.py \
--dsout mytrain.csv \
--funcx "np.sqrt(np.abs(x))" \
--xbegin -6.0 \
--xend 6.0 \
--xstep 0.01fxy_gen.py
Scopo del programma Python fxy_gen.py
è di generare un dataset sintetico in formato csv (con header) a partire da una funzione scalare reale di due variabili reali in un rettangolo chiuso specificando i passi di discretizzazione.
Il file csv in uscita ha tre colonne (con header): le prime due colonne contengono i valori delle due variabili indipendenti $x$ e $y$ nel rettangolo desiderato con i passi di discretizzazione specificati;
la terza colonna contiene i valori della variabile dipendente, ovverosia i valori della funzione $f(x,y)$ corrispondenti al valore di $x$ e di $y$ delle prime due colonne.
Per ottenere l'usage del programma è sufficiente eseguire il seguente comando:
$ python fxy_gen.py --helpusage: fxy_gen.py [-h] [--version] --dsout DS_OUTPUT_FILENAME --funcxy
FUNC_XY_BODY [--xbegin RANGE_XBEGIN] [--xend RANGE_XEND]
[--ybegin RANGE_YBEGIN] [--yend RANGE_YEND]
[--xstep RANGE_XSTEP] [--ystep RANGE_YSTEP]
[--noise NOISE_BODY]
fxy_gen.py generates a synthetic dataset file calling a two-variables real
function on a rectangle
optional arguments:
-h, --help show this help message and exit
--version show program's version number and exit
--dsout DS_OUTPUT_FILENAME
dataset output file (csv format)
--funcxy FUNC_XY_BODY
f(x, y) body (lamba format)
--xbegin RANGE_XBEGIN
begin x range (default:-5.0)
--xend RANGE_XEND end x range (default:+5.0)
--ybegin RANGE_YBEGIN
begin y range (default:-5.0)
--yend RANGE_YEND end y range (default:+5.0)
--xstep RANGE_XSTEP step range of x (default: 0.01)
--ystep RANGE_YSTEP step range of y (default: 0.01)
--noise NOISE_BODY noise(sz) body (lamba format)-
-h, --help: mostra l'usage del programma e termina l'esecuzione.
-
--version: mostra la versione del programma e termina l'esecuzione.
-
--dsout: percorso (relativo o assoluto) del file csv da generare ed è ottenuto eseguendo la funzione generatrice del dataset.
-
--funcxy: la funzione generatrice $y=f(x,y)$ del dataset in formato lamba body ove $x$ e $y$ sono le variabili indipendenti.
-
--xbegin e --xend: intervallo chiuso della variabile indipendente $x$ tra
--xbegine--xend.
-
--ybegin e --yend: intervallo chiuso della variabile indipendente $y$ tra
--ybegine--yend.
-
--xstep: passo di discretizzazione della variable indipendente $x$.
-
--ystep: passo di discretizzazione della variable indipendente $y$.
-
--noise: la funzione generatrice di rumore in formato lamba body, ove $sz$ è
il numero di elementi del rettangolo discretizzato tra
--xbegine--xendper--ybegine--yend.
Un esempio di uso del programma fxy_gen.py
Si supponga di voler approssimare nel rettangolo $[-6.0,6.0]\times[-6.0,6.0]$ la seguente funzione $$\sin \sqrt{x^2 + y^2}$$, Tenendo presente che np è l'alias della libreria NumPy, questa si traduce in sintassi lambda body Python così:
np.sin(np.sqrt(x**2 + y**2))$ python fxy_gen.py \
--dsout mytrain.csv \
--funcxy "np.sin(np.sqrt(x**2 + y**2))" \
--xbegin -6.0 \
--xend 6.0 \
--ybegin -6.0 \
--yend 6.0 \
--xstep 0.075 \
--ystep 0.075pmc2t_gen.py
Scopo del programma Python pmc2t_gen.py
è di generare una dataset a partire da una coppia di funzioni reali di una variabile $t$, detta parametro:
prende in linea di comando le due funzioni componenti da approssimare (in sintassi lambda body), l'intervallo del parametro indipendente $t$ (inizio, fine e passo di discretizzazione)
e genera il dataset in un file nel formato csv applicando le due funzione all'intervallo del parametro $t$ passato.
Il file csv in uscita ha infatti tre colonne (con header): la prima colonna contiene i valori, ordinati in modo crescente, del parametro indipendente $t$ nell'intervallo desiderato con il passo di discretizzazione specificato;
la seconda colonna e terza colonna contengono rispettivamente i valori delle componenti $x$ e $y$, ovverosia i valori delle funzioni $x(t)$ e $y(t)$ corrispondenti al valore di $t$ della prima colonna.
Per ottenere l'usage del programma è sufficiente eseguire il seguente comando:
$ python pmc2t_gen.py --helpusage: pmc2t_gen.py [-h] [--version] --dsout DS_OUTPUT_FILENAME --funcxt
FUNCX_T_BODY --funcyt FUNCY_T_BODY [--tbegin RANGE_BEGIN]
[--tend RANGE_END] [--tstep RANGE_STEP]
[--xnoise XNOISE_BODY] [--ynoise YNOISE_BODY]
pmc2t_gen.py generates a synthetic dataset file that contains the points of a
parametric curve on plane calling a couple of one-variable real functions in
an interval
optional arguments:
-h, --help show this help message and exit
--version show program's version number and exit
--dsout DS_OUTPUT_FILENAME
dataset output file (csv format)
--funcxt FUNCX_T_BODY
x=x(t) body (lamba format)
--funcyt FUNCY_T_BODY
y=y(t) body (lamba format)
--tbegin RANGE_BEGIN begin range (default:-5.0)
--tend RANGE_END end range (default:+5.0)
--tstep RANGE_STEP step range (default: 0.01)
--xnoise XNOISE_BODY noise(sz) body (lamba format) on x
--ynoise YNOISE_BODY noise(sz) body (lamba format) on y-
-h, --help: mostra l'usage del programma e termina l'esecuzione.
-
--version: mostra la versione del programma e termina l'esecuzione.
-
--dsout: percorso (relativo o assoluto) del file csv da generare ed è ottenuto eseguendo la funzione generatrice del dataset.
-
--funcxt: la funzione generatrice $x=fx(t)$ del dataset in formato lamba body ove $t$ è la variabile indipendente.
-
--funcyt: la funzione generatrice $y=fy(t)$ del dataset in formato lamba body ove $t$ è la variabile indipendente.
-
--tbegin e --tend: intervallo chiuso della variabile indipendente $t$ tra
--tbegine--tend.
-
--tstep: passo di discretizzazione della variable indipendente $t$.
-
--xnoise: la funzione generatrice di rumore sulla variable $x$ in formato lamba body, ove $sz$ è
il numero di elementi dell'intervallo discretizzato tra
--tbegine--tend.
-
--ynoise: la funzione generatrice di rumore sulla variable $y$ in formato lamba body, ove $sz$ è
il numero di elementi del discretizzato tra
--tbegine--tend.
pmc3t_gen.py
Scopo del programma Python pmc3t_gen.py
è di generare una dataset a partire da una tripla di funzioni reali di una variabile $t$, detta parametro:
prende in linea di comando le tre funzioni componenti da approssimare (in sintassi lambda body), l'intervallo del parametro indipendente $t$ (inizio, fine e passo di discretizzazione)
e genera il dataset in un file nel formato csv applicando le tre funzione all'intervallo del parametro $t$ passato.
Il file csv in uscita ha infatti quattro colonne (con header): la prima colonna contiene i valori, ordinati in modo crescente, del parametro indipendente $t$ nell'intervallo desiderato con il passo di discretizzazione specificato;
la seconda colonna, terza e quarta colonna contengono rispettivamente i valori delle componenti $x$, $y$ e $z$, ovverosia i valori delle funzioni $x(t)$, $y(t)$ e $z(t)$ corrispondenti al valore di $t$ della prima colonna.
Per ottenere l'usage del programma è sufficiente eseguire il seguente comando:
$ python pmc3t_gen.py --helpusage: pmc3t_gen.py [-h] [--version] --dsout DS_OUTPUT_FILENAME --funcxt
FUNCX_T_BODY --funcyt FUNCY_T_BODY --funczt FUNCZ_T_BODY
[--tbegin RANGE_BEGIN] [--tend RANGE_END]
[--tstep RANGE_STEP] [--xnoise XNOISE_BODY]
[--ynoise YNOISE_BODY] [--znoise ZNOISE_BODY]
pmc3t_gen.py generates a synthetic dataset file that contains the points of a
parametric curve in space calling a a triple of one-variable real functions in
an interval
optional arguments:
-h, --help show this help message and exit
--version show program's version number and exit
--dsout DS_OUTPUT_FILENAME
dataset output file (csv format)
--funcxt FUNCX_T_BODY
x=x(t) body (lamba format)
--funcyt FUNCY_T_BODY
y=y(t) body (lamba format)
--funczt FUNCZ_T_BODY
z=z(t) body (lamba format)
--tbegin RANGE_BEGIN begin range (default:-5.0)
--tend RANGE_END end range (default:+5.0)
--tstep RANGE_STEP step range (default: 0.01)
--xnoise XNOISE_BODY noise(sz) body (lamba format) on x
--ynoise YNOISE_BODY noise(sz) body (lamba format) on y
--znoise ZNOISE_BODY noise(sz) body (lamba format) on z-
-h, --help: mostra l'usage del programma e termina l'esecuzione.
-
--version: mostra la versione del programma e termina l'esecuzione.
-
--dsout: percorso (relativo o assoluto) del file csv da generare ed è ottenuto eseguendo la funzione generatrice del dataset.
-
--funcxt: la funzione generatrice $x=fx(t)$ del dataset in formato lamba body ove $t$ è la variabile indipendente.
-
--funcyt: la funzione generatrice $y=fy(t)$ del dataset in formato lamba body ove $t$ è la variabile indipendente.
-
--funczt: la funzione generatrice $z=fz(t)$ del dataset in formato lamba body ove $t$ è la variabile indipendente.
-
--tbegin e --tend: intervallo chiuso della variabile indipendente $t$ tra
--tbegine--tend.
-
--tstep: passo di discretizzazione della variable indipendente $t$.
-
--xnoise: la funzione generatrice di rumore sulla variable $x$ in formato lamba body, ove $sz$ è
il numero di elementi dell'intervallo discretizzato tra
--tbegine--tend.
-
--ynoise: la funzione generatrice di rumore sulla variable $y$ in formato lamba body, ove $sz$ è
il numero di elementi del discretizzato tra
--tbegine--tend.
-
--znoise: la funzione generatrice di rumore sulla variable $z$ in formato lamba body, ove $sz$ è
il numero di elementi del discretizzato tra
--tbegine--tend.
Visualizzazione comparata dei dataset
Questo capitolo illustra gli strumenti per la visualizzazione dei dataset permettendo di confrontare visualmente i dataset di input con la predizione generata dagli approssimatori.
fx_scatter.py
Scopo del programma Python fx_scatter.py
è quello di visualizzare il grafico a dispersione della predizione di una funzione scalare reale di una variabile reale
sovrapposto al grafico a dispersione del dataset di input della funzione originale e consentire la comparazione visuale dei due grafici.
Per ottenere l'usage del programma è sufficiente eseguire il seguente comando:
$ python fx_scatter.py --helpusage: fx_scatter.py [-h] [--version] --ds DATASET_FILENAME --prediction
PREDICTION_DATA_FILENAME [--title FIGURE_TITLE]
[--xlabel X_AXIS_LABEL] [--ylabel Y_AXIS_LABEL]
[--labelfontsize LABEL_FONT_SIZE] [--width WIDTH]
[--height HEIGHT] [--savefig SAVE_FIGURE_FILENAME]
fx_scatter.py shows two overlapped x/y scatter graphs: the blue one is the
input dataset, the red one is the prediction
optional arguments:
-h, --help show this help message and exit
--version show program's version number and exit
--ds DATASET_FILENAME
dataset file (csv format)
--prediction PREDICTION_DATA_FILENAME
prediction data file (csv format)
--title FIGURE_TITLE if present, it set the title of chart
--xlabel X_AXIS_LABEL
label of x axis
--ylabel Y_AXIS_LABEL
label of y axis
--labelfontsize LABEL_FONT_SIZE
label font size
--width WIDTH width of whole figure (in inch)
--height HEIGHT height of whole figure (in inch)
--savefig SAVE_FIGURE_FILENAME
if present, the figure is saved on a file instead to be
shown on screen-
-h, --help: mostra l'usage del programma e termina l'esecuzione.
-
--version: mostra la versione del programma e termina l'esecuzione.
-
--ds: percorso (relativo o assoluto) del dataset di input; il suo grafico a dispersione è di colore blu.
-
--prediction: percorso (relativo o assoluto) del file di predizione (sempre in formato csv); il suo grafico a dispersione è di colore rosso.
-
--title: titolo della figura, centrato in alto.
-
--xlabel: testo dell'asse $x$.
-
--ylabel: testo dell'asse $y$.
-
--labelfontsize: dimensione del font di tutte le label presenti nell'intera figura.
-
--width: larghezza dell'intera figura (in pollici).
-
--height: altezza dell'intera figura (in pollici).
-
--savefig:
se presente, è il percorso (relativo o assoluto) del file in formato .png in cui è salvata l'intera figura;
se non presente, il grafico è visualizzato a video.
Un esempio di uso del programma fx_scatter.py
Avendo a disposizione il dataset di test mytest.csv (ad esempio generato tramite fx_gen.py come mostrato in un paragrafo precedente)
e il file csv della predizione mypred.csv (generato tramite tramite un programma di predizione presente nel repository per l'approssimazione delle funzioni ad una variabile),
per generare i due grafici si esegua il seguente comando:
$ python fx_scatter.py \
--ds mytest.csv \
--prediction mypred.csv \
--title "My example" \
--xlabel "x" \
--ylabel "y=|sin(x^x)/2^(x^x-pi/2)/pi|"
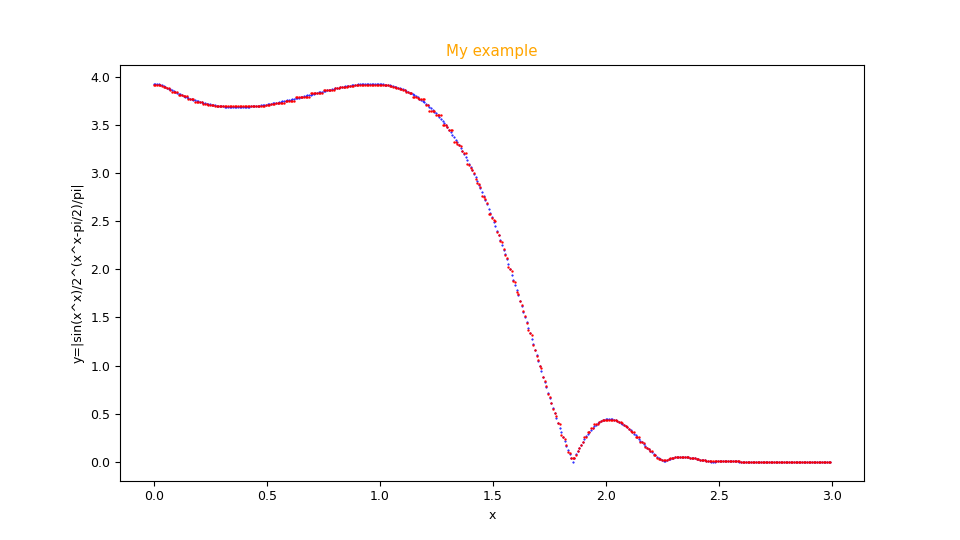
Figura con grafici a dispersione generata dal programma
fx_scatter.py che mostra l'approssimazione in sovraimpressione in rosso della funzione $f(x)=|\frac{\sin x^x}{2 ^ {(x^x - \pi/2)/\pi}}|$
e la funzione originale sottostante in blu.fxy_scatter.py
Scopo del programma Python fxy_scatter.py
è quello di visualizzare il grafico a dispersione della predizione di una funzione scalare reale di due variabili reali
affiancato al grafico a dispersione del dataset di input della funzione originale e consentire la comparazione visuale dei due grafici.
Per ottenere l'usage del programma è sufficiente eseguire il seguente comando:
$ python fxy_scatter.py --helpusage: fxy_scatter.py [-h] [--version] --ds DATASET_FILENAME --prediction
PREDICTION_DATA_FILENAME [--title FIGURE_TITLE]
[--xlabel X_AXIS_LABEL] [--ylabel Y_AXIS_LABEL]
[--zlabel Z_AXIS_LABEL]
[--labelfontsize LABEL_FONT_SIZE] [--width WIDTH]
[--height HEIGHT] [--savefig SAVE_FIGURE_FILENAME]
fxy_scatter.py: error: the following arguments are required: --ds, --prediction
(base) malkuth:common ettore$ python fxy_scatter.py --help
usage: fxy_scatter.py [-h] [--version] --ds DATASET_FILENAME --prediction
PREDICTION_DATA_FILENAME [--title FIGURE_TITLE]
[--xlabel X_AXIS_LABEL] [--ylabel Y_AXIS_LABEL]
[--zlabel Z_AXIS_LABEL]
[--labelfontsize LABEL_FONT_SIZE] [--width WIDTH]
[--height HEIGHT] [--savefig SAVE_FIGURE_FILENAME]
fxy_scatter.py shows two alongside x/y/z scatter graphs: the blue one is the
surface of dataset, the red one is the surface of prediction
optional arguments:
-h, --help show this help message and exit
--version show program's version number and exit
--ds DATASET_FILENAME
dataset file (csv format)
--prediction PREDICTION_DATA_FILENAME
prediction data file (csv format)
--title FIGURE_TITLE if present, it set the title of chart
--xlabel X_AXIS_LABEL
label of x axis
--ylabel Y_AXIS_LABEL
label of y axis
--zlabel Z_AXIS_LABEL
label of z axis
--labelfontsize LABEL_FONT_SIZE
label font size
--width WIDTH width of animated git (in inch)
--height HEIGHT height of animated git (in inch)
--savefig SAVE_FIGURE_FILENAME
if present, the chart is saved on a file instead to be
shown on screen-
-h, --help: mostra l'usage del programma e termina l'esecuzione.
-
--version: mostra la versione del programma e termina l'esecuzione.
-
--ds: percorso (relativo o assoluto) del dataset di input; il suo grafico a dispersione è di colore blu.
-
--prediction: percorso (relativo o assoluto) del file di predizione (sempre in formato csv); il suo grafico a dispersione è di colore rosso.
-
--title: titolo del grafico, centrato in alto.
-
--xlabel: testo dell'asse $x$.
-
--ylabel: testo dell'asse $y$.
-
--zlabel: testo dell'asse $z$.
-
--labelfontsize: dimensione del font di tutte le label presenti nell'intera figura.
-
--width e --height: larghezza e altezza dell'intera figura (in pollici).
-
--savefig:
se presente, è il percorso (relativo o assoluto) del file in formato .png in cui è salvata l'intera figura;
se non presente, il grafico è visualizzato a video.
Un esempio di uso del programma fxy_scatter.py
Avendo a disposizione il dataset di test mytest.csv (ad esempio generato tramite fx_gen.py come mostrato in un paragrafo precedente)
e il file csv della predizione mypred.csv (generato tramite tramite un programma di predizione presente nel repository per l'approssimazione delle funzioni ad una variabile),
per generare i due grafici si esegua il seguente comando:
$ python fxy_scatter.py \
--ds mytest.csv \
--prediction mypred.csv \
--title "My example" \
--xlabel "x" \
--ylabel "y" \
--zlabel "z=2 sin(x)^2 / sqrt(1+y^2)"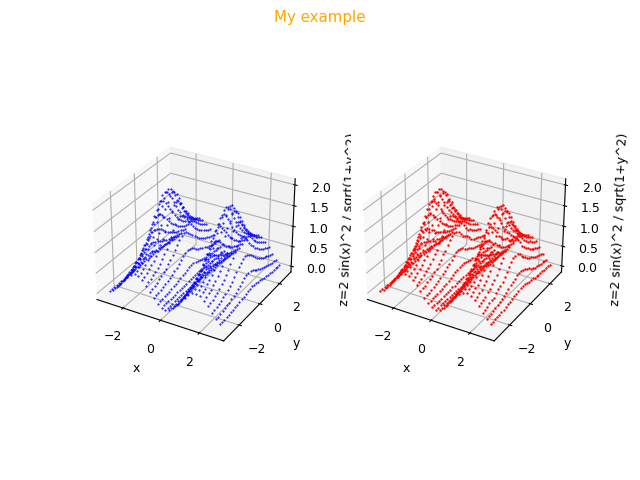
Figura con grafici a dispersione generata dal programma
fxy_scatter.py che mostra l'approssimazione a destra in rosso della funzione $f(x,y)=2 \frac{\sin^2 x}{\sqrt{1 + y^2}}$
e la funzione originale accanto in blu a sinistra.pmc2t_scatter.py
Scopo del programma Python pmc2t_scatter.py
è quello di visualizzare il grafico a dispersione della predizione di una curva parametrica sul piano
sovrapposto al grafico a dispersione del dataset di input della curva parametrica originale e consentire la comparazione visuale dei due grafici.
Per ottenere l'usage del programma è sufficiente eseguire il seguente comando:
$ python pmc2t_scatter.py --helpusage: pmc2t_scatter.py [-h] [--version] --ds DATASET_FILENAME --prediction
PREDICTION_DATA_FILENAME [--title FIGURE_TITLE]
[--xlabel X_AXIS_LABEL] [--ylabel Y_AXIS_LABEL]
[--labelfontsize LABEL_FONT_SIZE] [--width WIDTH]
[--height HEIGHT] [--savefig SAVE_FIGURE_FILENAME]
pmc2t_scatter.py shows two overlapped x/y scatter graphs on plane: the blue
one is the input dataset of parametric curve, the red one is the prediction of
parametric curve
optional arguments:
-h, --help show this help message and exit
--version show program's version number and exit
--ds DATASET_FILENAME
dataset file (csv format)
--prediction PREDICTION_DATA_FILENAME
prediction data file (csv format)
--title FIGURE_TITLE if present, it set the title of chart
--xlabel X_AXIS_LABEL
label of x axis
--ylabel Y_AXIS_LABEL
label of y axis
--labelfontsize LABEL_FONT_SIZE
label font size
--width WIDTH width of whole figure (in inch)
--height HEIGHT height of whole figure (in inch)
--savefig SAVE_FIGURE_FILENAME
if present, the figure is saved on a file instead to
be shown on screen-
-h, --help: mostra l'usage del programma e termina l'esecuzione.
-
--version: mostra la versione del programma e termina l'esecuzione.
-
--ds: percorso (relativo o assoluto) del dataset di input; il suo grafico a dispersione è di colore blu.
-
--prediction: percorso (relativo o assoluto) del file di predizione (sempre in formato csv); il suo grafico a dispersione è di colore rosso.
-
--title: titolo del grafico, centrato in alto.
-
--xlabel: testo dell'asse $x$.
-
--ylabel: testo dell'asse $y$.
-
--labelfontsize: dimensione del font di tutte le label presenti nell'intera figura.
-
--width e --height: larghezza e altezza dell'intera figura (in pollici).
-
--savefig:
se presente, è il percorso (relativo o assoluto) del file in formato .png in cui è salvata l'intera figura;
se non presente, il grafico è visualizzato a video.
pmc3t_scatter.py
Scopo del programma Python fxy_scatter.py
è quello di visualizzare il grafico a dispersione di una curva parametrica nello spazio
sovrapposto al grafico a dispersione del dataset di input della curva parametrica originale e consentire la comparazione visuale dei due grafici.
Per ottenere l'usage del programma è sufficiente eseguire il seguente comando:
$ python pmc3t_scatter.py --help -h, --help show this help message and exit
--version show program&aposMs version number and exit
--ds DATASET_FILENAME
dataset file (csv format)
--prediction PREDICTION_DATA_FILENAME
prediction data file (csv format)
--title FIGURE_TITLE if present, it set the title of chart
--xlabel X_AXIS_LABEL
label of x axis
--ylabel Y_AXIS_LABEL
label of y axis
--zlabel Z_AXIS_LABEL
label of z axis
--labelfontsize LABEL_FONT_SIZE
label font size
--width WIDTH width of whole figure (in inch)
--height HEIGHT height of whole figure (in inch)
--savefig SAVE_FIGURE_FILENAME
if present, the figure is saved on a file instead to
be shown on screen
-
-h, --help: mostra l'usage del programma e termina l'esecuzione.
-
--version: mostra la versione del programma e termina l'esecuzione.
-
--ds: percorso (relativo o assoluto) del dataset di input; il suo grafico a dispersione è di colore blu.
-
--prediction: percorso (relativo o assoluto) del file di predizione (sempre in formato csv); il suo grafico a dispersione è di colore rosso.
-
--title: titolo del grafico, centrato in alto.
-
--xlabel: testo dell'asse $x$.
-
--ylabel: testo dell'asse $y$.
-
--zlabel: testo dell'asse $z$.
-
--labelfontsize: dimensione del font di tutte le label presenti nell'intera figura.
-
--width e --height: larghezza e altezza dell'intera figura (in pollici).
-
--savefig:
se presente, è il percorso (relativo o assoluto) del file in formato .png in cui è salvata l'intera figura;
se non presente, il grafico è visualizzato a video.
Diagnostica
Questo capitolo illustra gli strumenti per la diagnostica messi a disposizione da questo repository per l'approssimazione delle funzioni; i programmi di questo repository che implementano le feature di addestramento salvano (se l'utente lo desidera) file di dump utilizzabili successivamente e/o durante la fase di training dai programmi qui descritti con il fine di analizzare come sia avvenuta (o sia avvenendo) la fase di training e quindi operare sugli iper parametri per migliorarne il risultato finale.
dumps_scatter.py
Scopo del programma Python dumps_scatter.py
è quello di visualizzare i grafici della funzione di loss e delle varie metriche calcolate durante la fase di training.
Affinché sia possibile utilizzare questo programma è necessario che i programmi di training siano stati lanciati
con gli opportuni argomenti per salvare i file di dump della funzione di loss e/o delle metriche al passare delle epoche.
Per ottenere l'usage del programma è sufficiente eseguire il seguente comando:
$ python dumps_scatter.py --helpusage: dumps_scatter.py [-h] [--version] --dump DUMP_PATH
[--savefigdir SAVE_FIGURE_DIRECTORY]
dumps_scatter.py shows the loss and metric graphs with data generated by
any fitting program with argument --dumpout
optional arguments:
-h, --help show this help message and exit
--version show program's version number and exit
--dump DUMP_PATH Dump directory (generated by any fitting/training
programs of this suite that support --dumpout
argument)
--savefigdir SAVE_FIGURE_DIRECTORY
If present, the charts are saved on files in
savefig_dir folder instead to be shown on screen-
-h, --help: mostra l'usage del programma e termina l'esecuzione.
-
--version: mostra la versione del programma e termina l'esecuzione.
-
--dump: percorso (relativo o assoluto) della directory dove sono stati salvati i dump della funzione di loss e/o delle metriche durante il training allo scorrere delle epoche.
-
--savefigdir:
se presente, è il percorso (relativo o assoluto) della directory in cui il programma salva le figure in formato .png, una figura per ciascun grafico per cui esiste il corrispondente file di dump;
se non presente, i grafici sono visualizzati a video.
Un esempio di uso del programma dumps_scatter.py
Avendo a disposizione la directory mydumps che contiene i file di dump di alcune metriche calcolate durante la fase di addestramento
di un qualche programma di training di questo repository, per visualizzare i grafici di tali metriche si esegua il seguente comando:
$ python dumps_scatter.py \
--dump mydumpsmydumps, come mostrato nelle seguenti figure.
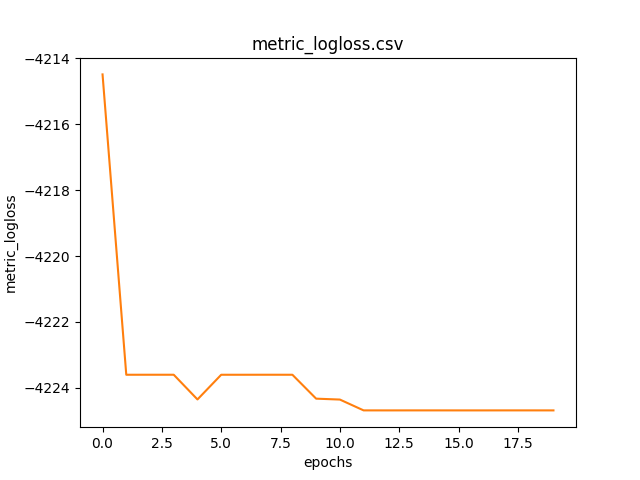
Grafico della metrica logloss al passare delle epoche calcolata sul dataset di training.
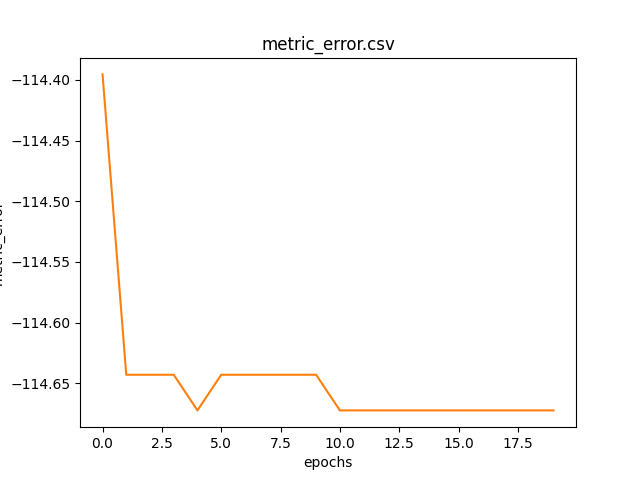
Grafico della metrica error al passare delle epoche calcolata sul dataset di training.
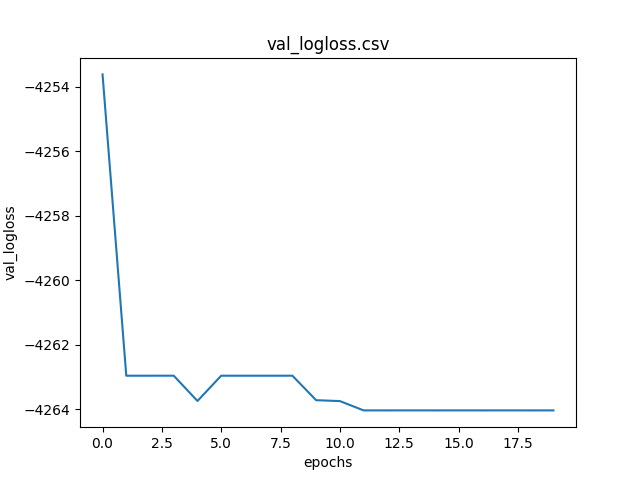
Grafico della metrica logloss al passare delle epoche calcolata sul dataset di validazione.
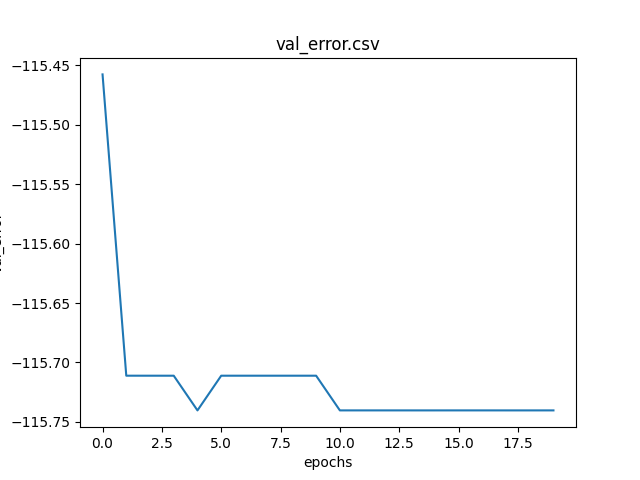
Grafico della metrica error al passare delle epoche calcolata sul dataset di validazione.
Download del codice completo
Il codice completo è disponibile su GitHub.
Questo materiale è distribuito su licenza MIT; sentiti libero di usare, condividere, "forkare" e adattare tale materiale come credi.
Sentiti anche libero di pubblicare pull-request e bug-report su questo repository di GitHub oppure di contattarmi sui miei canali social disponibili nell'angolo in alto a destra di questa pagina.